what are the steps to produce an olap cube

1 of the biggest shifts in information analytics over the by decade is the movement away from building 'data cubes', or 'OLAP cubes', to running OLAP* workloads direct on columnar databases.
(*OLAP means online analytical processing, but nosotros'll get into what that ways in a fleck).
This is a huge change, especially if you lot've congenital your career in information analytics over the past three decades. It may seem baroque to you lot that OLAP cubes — which were and then ascendant over the past 50 years of business intelligence — are going away. And you might be rightly skeptical of this shift to columnar databases. What are the tradeoffs? What are the costs? Is this move really equally good as all the new vendors say that information technology is? And of course, at that place'southward that phonation at the back of your head, asking: is this merely another fad that will go away, like the NoSQL motion before information technology? Will information technology even last?
This essay seeks to be an exhaustive resources on the history and evolution of the OLAP cube, and the current shift away from it. Nosotros'll start with definitions of the terminology (OLAP vs OLTP), cover the emergence of the OLAP cube, and and so explore the emergence of columnar data warehouses equally an alternative approach to OLAP workloads.
This piece is written with the novice in heed. If you're a more experienced data analytics person, feel free to skip the commencement few sections, in social club to get to the interesting parts at the end of this piece. Let's dive in.
What the Heck is OLAP?
Online Belittling Processing (or OLAP) is a fancy term used to describe a certain class of database applications. The term was invented past database legend Edgar F. Codd, in a 1993 newspaper titled Providing OLAP to User-Analysts: An It Mandate.
Codd's creation of the term wasn't without controversy. A twelvemonth before he published the paper, Arbor Software had released a software product chosen Essbase, and — surprise, surprise! — Codd's paper divers properties that happened to fit Essbase's feature set perfectly.
Computerworld magazine presently discovered that Arbor had paid Codd to 'invent' OLAP as a new category of database applications, in social club to meliorate sell its product. Codd got called out for his conflict of interest and was forced to retract his paper … but without much fallout, it seems: today, Codd is still regarded every bit 'the father of the relational database', and OLAP has stuck around as a category always since.
'And so what is OLAP?' you might inquire. The easiest way to explain this is to draw the ii types of business concern application usage. Let's say that yous run a machine dealership. There are two kinds of database-backed operations that you need to do:
- Y'all need to utilize a database every bit part of some business organisation process. For case, your salesperson sells the latest Honda Borough to a customer, and you need to tape this transaction in a concern awarding. Yous do this for operational reasons: you lot need a manner to keep track of the deal, you lot need a manner to contact the customer when the car loan or insurance is finally approved, and you need it to calculate sales bonuses for your salesperson at the end of the month.
- You lot employ a database as office of assay. Periodically, you lot will demand to collate numbers to understand how your overall business is doing. In his 1993 paper, Codd chosen this activity 'conclusion-making-support'. These queries are things like 'how many Honda Civics were sold in London the last 3 months?' and 'who are the most productive salespeople?' and 'are sedans or SUVs selling improve overall?' These are questions you lot enquire at the terminate of a month or a quarter to guide your business planning for the near hereafter.
The first category of database usage is known equally 'Online Transaction Processing', or 'OLTP'. The second category of database usage is known as 'Online Analytical Processing', or 'OLAP'.
Or, every bit I like to think of it:
- OLTP: using a database to run your business organization
- OLAP: using a database to understand your business
Why do we care for these two categories differently? As information technology turns out, the ii usage types accept vastly dissimilar data-access patterns.
With OLTP, you lot run things like 'tape a sales transaction: one Honda Civic past Jane Doe in the London branch on the 1st of January, 2020'.
With OLAP, your queries tin become incredibly complex: 'give me the full sales of light-green Honda Civics in the UK for the past half dozen months' or 'tell me how many cars Jane Doe sold concluding calendar month', and 'tell me how well did Honda cars practise this quarter in comparison to the previous quarter'? The queries in the latter category aggregate information beyond many more elements when compared to the queries for the one-time.
In our example of a car dealership, you might be able to get a way with running both OLTP and OLAP query-types on a normal relational database. Merely if you lot deal with huge amounts of data — if you're querying a global database of car sales over the past decade, for instance — information technology becomes important to structure your information for assay separately from the business application. Not doing and then would result in severe operation problems.
The Performance Challenges of OLAP
To give you lot an intuition for the kinds of performance difficulties we're talking about, recall virtually the queries you must ask when you lot're analyzing car sales at a car dealership.
- requite me the total sales of dark-green Honda Civics in the United kingdom of great britain and northern ireland for the past 6 months
- tell me how many cars Jane Doe sold last month
- how many Honda cars did we sell this quarter in comparison to the previous quarter?
These queries can be reduced to a number of dimensions — backdrop that nosotros want to filter by. For case, yous might want to think data that is aggregated past:
- date (including calendar month, year, and day)
- motorcar model
- car manufacturer
- salesperson
- car colour
- transaction amount
If you were to store these pieces of information in a typical relational database, you would be forced to write something similar this to retrieve a 3 dimensional summary table:
SELECT Model, ALL, ALL, SUM(Sales) FROM Sales WHERE Model = 'Civic' Grouping By Model UNION SELECT Model, Month, ALL, SUM(Sales) FROM Sales WHERE Model = 'Civic' Group Past Model, Year Wedlock SELECT Model, Twelvemonth, Salesperson, SUM(Sales) FROM Sales WHERE Model = 'Civic' GROUP BY Model, Year, Salesperson; A 3-dimensional roll-up requires 3 such unions. This is generalisable: it turns out that aggregating over North dimensions require Northward such unions.
You might think that this is already pretty bad, just this isn't the worst case there is. Permit's say that you want to do a cross-tabulation, or what Excel power users call a 'pivot table'. An example of a cantankerous-tabulation looks similar this:
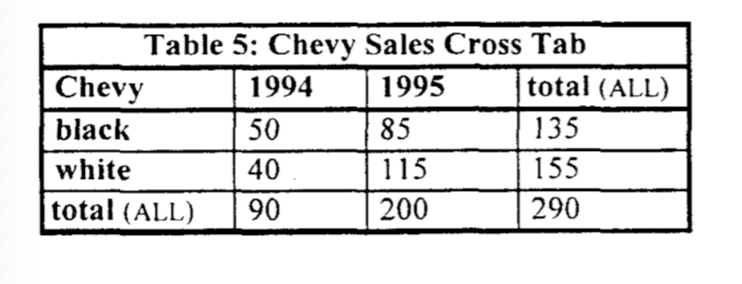
Cross-tabulations require an even more complicated combination of unions and GROUP Past clauses. A six dimensional cantankerous-tabulation, for instance, requires a 64-way spousal relationship of 64 different GROUP BY operators to build the underlying representation. In near relational databases, this results in 64 scans of the information, 64 sorts or hashes, and a terribly long await.
Business organization intelligence practitioners realised pretty early that information technology was a bad idea to use SQL databases for large OLAP workloads. This was made worse past the fact that computers weren't peculiarly powerful back in the day: in 1995, for instance, 1GB of RAM cost $32,300 — an insane toll for an amount of memory nosotros accept for granted today! This meant that the vast majority of business organisation users had to utilize relatively small memories to run BI workloads. Early on BI practitioners thus settled on a general approach: grab only the data you need out of your relational database, and and so shove it into an efficient in-memory data construction for manipulation.
The Rise of the OLAP Cube
Enter the OLAP cube, otherwise known equally the data cube.
The OLAP cube grew out of a simple idea in programming: accept information and put it into what is known every bit a '2-dimensional array' — that is, a listing of lists. The natural progression here is that the more dimensions yous wanted to clarify, the more nested arrays you would use: a 3-dimensional array is a list of list of lists, a 4-dimensional array is a list of listing of list of lists, and and then on. Considering nested arrays exist in all the major programming languages, the thought of loading information into such a data construction was an obvious 1 for the designers of early BI systems.
Simply what if you want to run analyses on datasets that are far larger than your computer's available retention? Early BI systems decided to exercise the next logical matter: they aggregated and and then cached subsets of data within the nested array — and occasionally persisted parts of the nested array to disk. Today, 'OLAP cubes' refer specifically to contexts in which these data structures far outstrip the size of the hosting computer's chief memory — examples include multi-terabyte datasets and time-serial of image data.
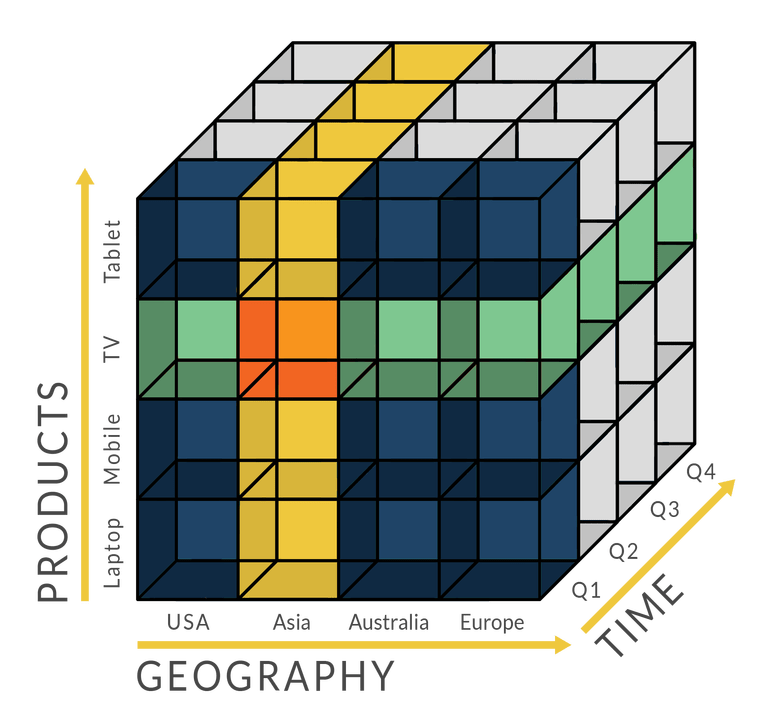
The bear on of the OLAP cube was profound — and changed the do of business intelligence to this very day. For starters, nearly all analysis began to be done within such cubes. This in turn meant that new cubes often had to exist created whenever a new report or a new analysis was required.
Say y'all want to run a report on car sales past province. If your currently available gear up of cubes don't include province information, yous'd take to ask a data engineer to create a new OLAP cube for y'all, or request that she modify an existing cube to include such province data.
OLAP cube usage also meant that data teams had to manage complicated pipelines to transform information from an SQL database into these cubes. If you were working with a large amount of data, such transformation tasks could take a long time to complete, so a common practice would be to run all ETL (excerpt-transform-load) pipelines before the analysts came in to work. This manner, the analysts wouldn't need to wait for their cubes to be loaded with the latest data — they could have the computers practice the data heavy-lifting at night, and get-go piece of work immediately in the mornings. This approach, of course, became more problematic as companies globalized, and opened offices in multiple timezones that demanded access to the same analytical systems. (How do yous run your pipelines at 'dark' when your dark is another office's morn?)
Using OLAP cubes in this way also meant that SQL databases and information warehouses had to be organized in away that made for easier cube creation. If you lot became a data analyst in the previous two decades, for case, information technology was highly likely that you were trained in the arcane arts of Kimball dimensional modeling, Inmon-style entity-human relationship modeling, or data vault modeling. These fancy names are simply methods for organizing the data in your data warehouse to lucifer your businesses'southward analytical requirements.
Kimball, Inmon and their peers observed that certain access patterns occured in every business organisation. They also observed that a slap-dash arroyo to information organisation was a terrible idea, given the corporeality of time data teams spent creating new cubes for reporting. Eventually, these early practitioners adult repeatable methods to turn business reporting requirements into data warehouse designs — designs that would make it easier for teams to extract the data they need in the formats they need for their OLAP cubes.
These constraints have shaped the form and function of data teams for the amend part of four decades. Information technology is of import to understand that very real technological constraints lead to the creation of the OLAP cube, and the demands of the OLAP cube led to the emergence of information squad practices that we take for granted today. For instance, we:
- Maintain complex ETL pipelines in order to model our information.
- Hire a large team of data engineers in order to maintain these complicated pipelines.
- Model data according to Kimball or Inmon or Data Vault frameworks in social club to get in easier to extract and load data into cubes. (And even when we've moved abroad from cubes, nosotros still keep these practices in order to load data into analytical and visualization tools — regardless of whether they're built on top of cubes.)
- Take the big team of data engineers also maintain these second fix of pipelines (from modelled information warehouse to cube).
Today, notwithstanding, many of the constraints that atomic number 82 to the creation of the data cube have loosened somewhat. Computers are faster. Memory is cheap. The deject works. And information practitioners are first to see that OLAP cubes come with a number of problems of their own.
Wither the OLAP Cube
Let'due south pretend for a moment that we live in a earth where retention is inexpensive and computing power is readily available. Let's also pretend that in this world, SQL databases are powerful plenty to come in both OLTP and OLAP flavours. What would this globe look similar?
For starters, we'd probably stop using OLAP cubes. This is stupidly obvious: why bother going through an actress step of building and generating new cubes when you can just write queries in an existing SQL database? Why bother maintaining a circuitous tapestry of pipelines if the data y'all need for reporting could be copied blindly from your OLTP database into your OLAP database? And why bother training your analysts in anything other than SQL?
This sounds like a tiny thing, only it isn't: nosotros've heard multiple horror stories from analysts who've had to depend on data engineers to build cubes and ready upwards pipelines for every new reporting requirement. If you were an analyst in this state of affairs, you would feel powerless to meet your deadlines. Your business users would cake on you; you lot would block on your data engineers; and your information engineer would most likely be grappling with the complexity of your information infrastructure. This is bad for everyone. Better to avoid the complexity completely.
2nd, if we lived in an alternate world where compute was cheap and retention was plentiful … well, nosotros would ditch serious data modeling efforts.
This sounds ridiculous until you lot retrieve nigh it from a first principles perspective. We model information co-ordinate to rigorous frameworks like Kimball or Inmon because we must regularly construct OLAP cubes for our analyses. Historically, this meant a period of serious schema blueprint. It as well meant a constant amount of busy-piece of work in lodge to maintain that design in our warehouses as business requirements and data sources change.
But if you lot no longer apply OLAP cubes for your assay, then you no longer have to extract data as regularly from your data warehouse. And if you no longer accept to extract information regularly from your data warehouse, then there's no reason to treat your data warehouse schema equally a precious thing. Why do all that decorated work, after all, if you could merely 'model' data by creating new 'modelled' tables or materialized views within your information warehouse … as and when you lot need it? This approach has all the functional benefits of traditional data modeling without the ceremony or the complication that goes with designing and maintaining a Kimball-fashion schema.
Let'southward discuss a physical instance: let'due south say that you think you've got your schema wrong. What do y'all practice? In our alternate universe, this problem is elementary to solve: you can simply dump the table (or toss the view) and create new ones. And since your reporting tools connect directly to your analytical database, this leads to little disruption: you don't have to rewrite a circuitous gear up of pipelines or change the way your cubes are created — because y'all don't have whatever cubes to create in the showtime place.
A New Paradigm Emerges
The good news is that this alternate universe isn't an alternate universe. It is the earth that we alive in today.
How did we go here? As far equally I can tell, in that location take been three breakthroughs over the past 2 decades — two of which are easy to understand. We'll deal with those two showtime, before exploring the 3rd in some item.
The kickoff breakthrough is a simple consequence of Moore's police: compute and memory have become real commodities, and are at present both ridiculously cheap and hands available via the cloud. Today, anyone with a working credit card tin can go to AWS or Google Cloud and have an arbitrarily powerful server spun upwardly for them inside minutes. This fact also applies to cloud-based data warehouses — companies are able to shop and clarify huge data sets with practically zero fixed costs.
The 2nd breakthrough is that most modern, deject-based data warehouses have what is known every bit a massively parallel processing (MPP) architecture. The central insight behind the development of MPP databases is actually really piece of cake to understand: instead of existence limited by the computational power and memory of a single calculator, you tin can radically boost the functioning of your query if you spread that query across hundreds if non thousands of machines. These machines volition then procedure their slice of the query, and laissez passer the results up the line for aggregation into a final result. The issue of all this piece of work is that you go ridiculous performance improvements: Google's BigQuery, for instance, is able to perform a full regex lucifer on 314 1000000 rows with no indices, and return a result inside 10 seconds (source).
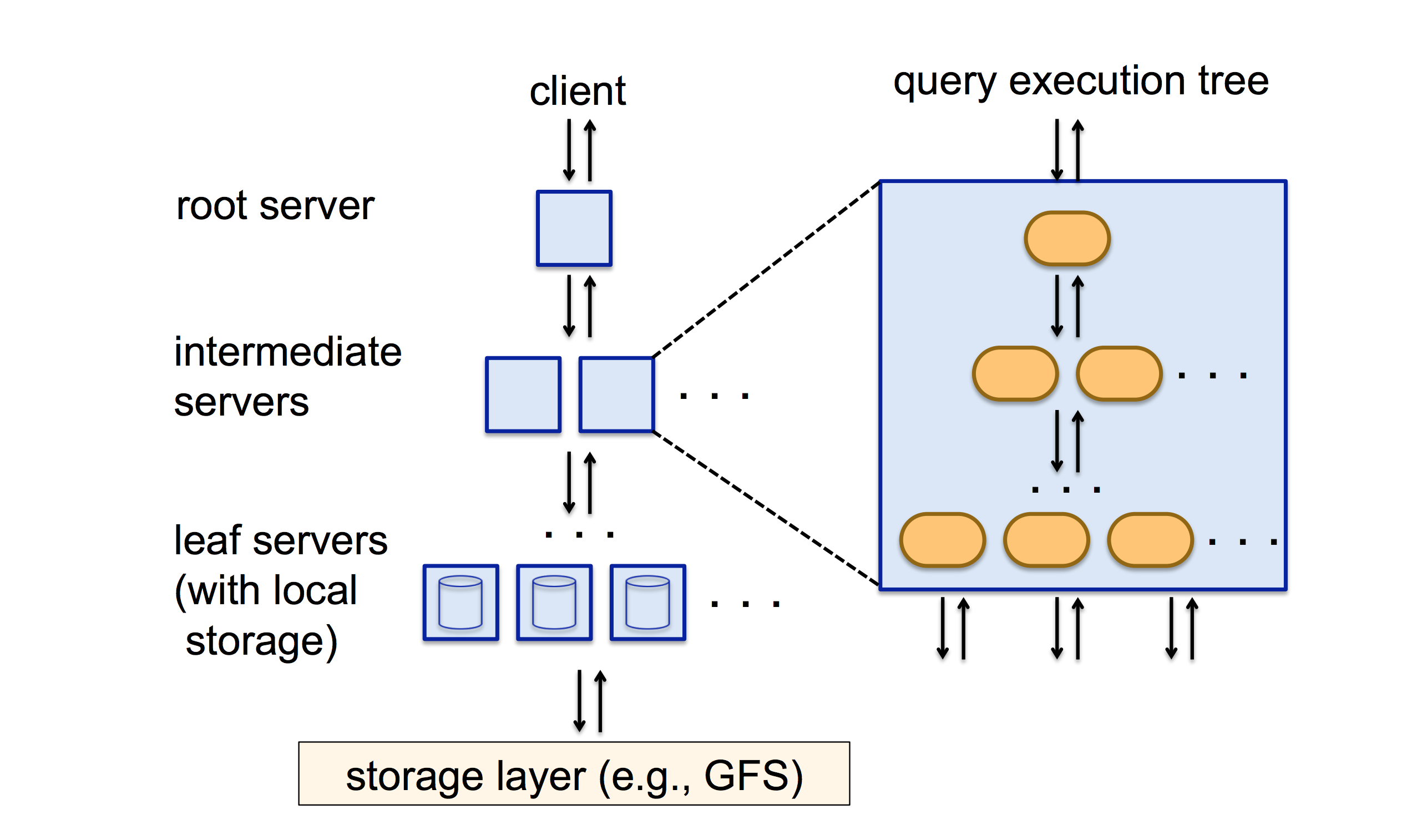
Information technology's like shooting fish in a barrel to sort of say "ahh MPP databases are a thing", but at that place has been at least 4 decades of work into making it into the reality it is today. In 1985, for example, database fable Michael Stonebraker published a paper titled The Example for Shared Nothing — an argument that the best architecture for an MPP information warehouse is one where processors don't share anything between each other. Several researchers pushed back against this view, with Much Ado About Shared Nix in 1996; my point here isn't to say Stonebraker was right and his critics wrong; information technology is to point out that at the beginning, even simple questions similar "should a distributed data warehouse have its computers share memory or storage or non?" was an open question in need of investigation. (If you're curious: the respond to that question is 'generally no').
The third breakthrough was the evolution and spread of columnar data warehouses. This conceptual breakthrough is actually the more important of the three, and it explains why OLAP workloads can shift away from cubes and dorsum into databases. We should understand why this is, if nosotros want to understand the future of business organisation intelligence.
A typical relational database stores its information in row grade. A single row for a transaction, for instance, would contain the fields date, customer, price, product_sku and then on. A columnar database, all the same, stores each of these fields in divide columns. As the illustration below shows (taken from this 2009 presentation by Harizopoulos, Abadi and Boncz):
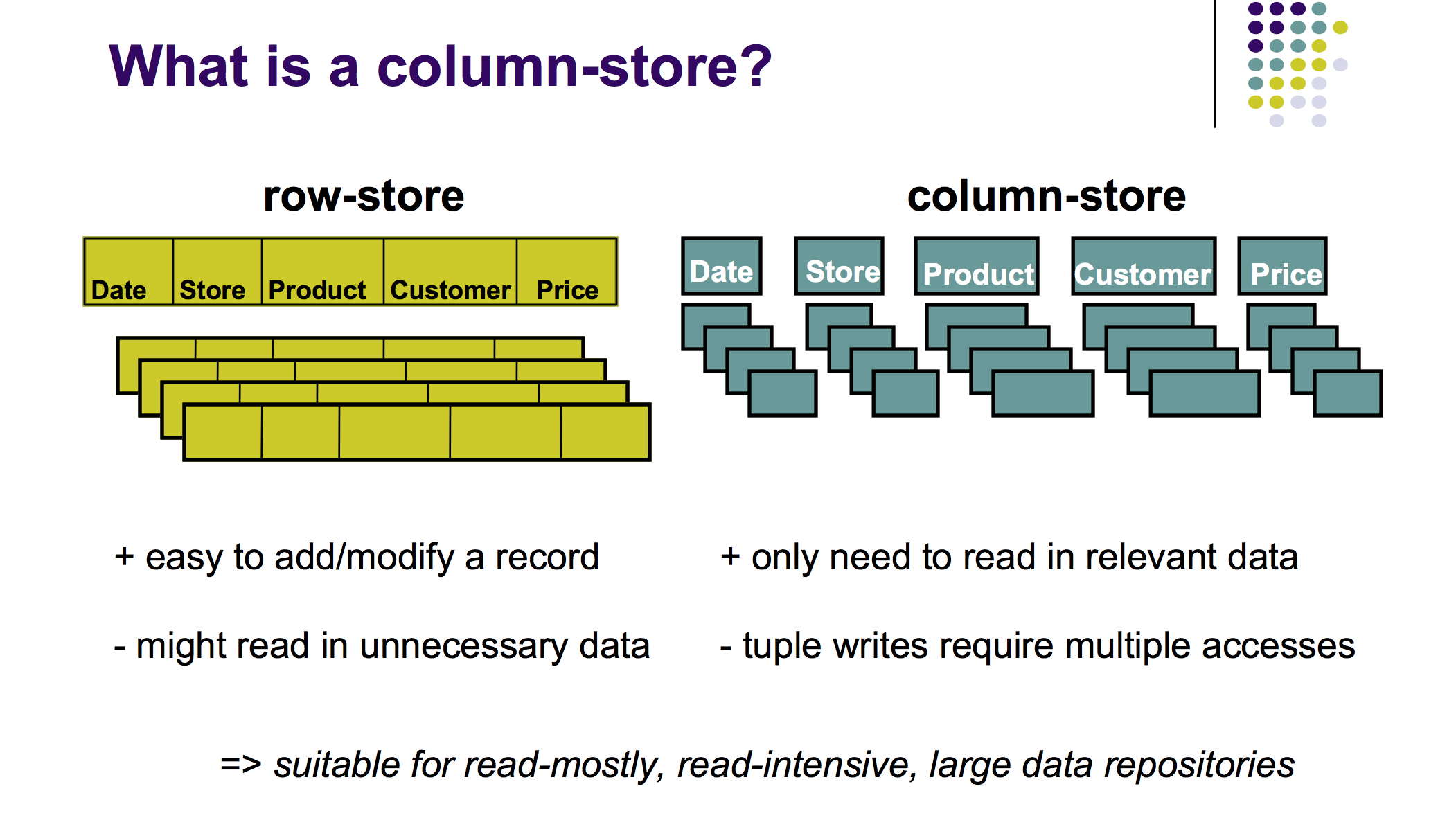
While OLAP cubes demand that you load a subset of the dimensions y'all're interested in into the cube, columnar databases allow yous to perform like OLAP-type workloads at equally good performance levels without the requirement to extract and build new cubes. In other words, this is an SQL database that is perfect for OLAP workloads.
How do columnar databases accomplish such feats of performance? As it turns out, in that location are three main benefits of storing your data in columns:
- Columnar databases have higher read efficiency. If you're running a query like "give me the average price of all transactions over the past 5 years", a relational database would have to load all the rows from the previous 5 years even though it merely wants to aggregate the cost field; a columnar database would but have to examine ane column — the price column. This ways that a columnar database merely has to sift through a fraction of the total dataset size.
- Columnar databases also shrink amend than row-based relational databases. It turns out that when yous're storing similar pieces of data together, you can compress it far better than if yous're storing very different pieces of information. (In information theory, this is what is known as 'low entropy'). Equally a reminder, columnar databases store columns of information — pregnant values with identical types and similar values. This is far easier to compress compared to row information, even if it comes at the cost of some compute (for decompression during certain operations) when you're reading values. But overall, this compression means more than data may be loaded into memory when you lot're running an aggregation query, which in plough results in faster overall queries.
- The last benefit is that pinch and dense-packing in columnar databases gratuitous up space — space that may be used to sort and index data inside the columns. In other words, columnar databases accept higher sorting and indexing efficiency, which comes more than every bit a side do good of having some leftover space from strong compression. It is also, in fact, mutually beneficial: researchers who study columnar databases point out that sorted data compress better than unsorted data, because sorting lowers entropy.
The net upshot of all these backdrop is that columnar databases give you lot OLAP cube-like operation without the pain of explicitly designing (and building!) cubes. Information technology ways you tin can perform everything you lot need within your data warehouse, and skip the laborious busy-work that comes with cube maintenance.
If there's a downside, however, it is that update performance in a columnar database is abysmal (you'll take to go to every column in club to update 1 'row'); every bit a outcome, many modernistic columnar databases limit your ability to update information after you've stored it. BigQuery, for instance, doesn't allow you to update data at all — you lot can only write new data to the warehouse, never edit old bits. (Update: the original Dremel paper explained that BigQuery had an append-merely structure; this is no longer true as of 2016).
Determination
What is the event of all these developments? The two predictions I made earlier when I was writing about the alternate universe are slowly coming truthful: smaller companies are less likely to consider data-cube-oriented tools or workloads, and strict dimensional modeling has become less important over fourth dimension. More importantly, tech-savvy companies like Amazon, Airbnb, Uber and Google have rejected the data cube paradigm entirely; these events and more tell me that we are going to see both trends spread into the enterprise over the next decade.
We are only at the start of this change, still. The future may be here, only it is unevenly distributed. This is but to exist expected: MPP columnar databases have only been around for a decade or and then (BigQuery launched in 2010, Redshift in 2012) and nosotros've only seen tools that take reward of this new epitome (like Looker, dbt and Holistics) emerge in the heart of the previous decade. Things are all the same actually early on — and nosotros have a long way to get before large enterprises toss out their legacy, cube-influenced systems and move to the new ones.
These trends may be interesting to y'all if you are a BI service provider, but let'due south focus a fiddling on the implications of these trends on your career. What does it mean for you if you are a data professional and OLAP cubes are on the wane?
As I encounter it, you'll accept to skate to where the puck is:
- Master SQL; the majority of MPP columnar databases have settled on SQL as the de-facto query standard. (More on this here).
- Be suspicious of companies that are heavily locked into the OLAP cube workflow. (Learn how to do this here).
- Familiarise yourself with modeling techniques for the columnar database historic period (Chartio is probably the showtime company I've seen with a guide that attempts this; read that hither … but sympathise that this is relatively new and the all-time practices may all the same be irresolute).
- Apply ELT whenever possible (as opposed to ETL); this is a effect of the new paradigm.
- Study Kimball, Inmon and data vault methodologies, but with an eye to application in the new image. Understand the limitations of each of their approaches.
I started this piece with a focus on the OLAP cube as a way to understand a core applied science in the history of business concern intelligence. But it turns out that the invention of the cube has been influential on nearly everything we've seen in our industry. Pay attention to its decline: if there'south nothing else you accept away from this piece, allow it be this: the rise and fall of the OLAP cube is more of import to your career than y'all might originally retrieve.
Follow up: We've published a follow up post titled: OLAP != OLAP Cube.
Sources
- https://en.wikipedia.org/wiki/Data_cube
- Kimball, Ross, The Data Warehouse Toolkit
- Dimensional Modeling and Kimball Data Marts in the Age of Large Data and Hadoop
- Data cube: a relational aggregation operator generalizing GROUP-BY, CROSS-TAB, and SUB-TOTALS (Gray, Bosworth, Lyaman, Pirahesh, 1997)
- Cuzzocrea A. (2010) OLAP Data Cube Pinch Techniques: A X-Year-Long History. In: Kim T., Lee Y., Kang BH., Ślęzak D. (eds) Hereafter Generation It. FGIT 2010. Lecture Notes in Computer Science, vol 6485. Springer, Berlin, Heidelberg
- OLAP: Past Nowadays and Hereafter?
- The Case for Shared Null, Michael Stonebraker and the response, Much Ado Nearly Shared Zip (Norman, Zurek, Thanisch)
- On BigQuery: the Dremel paper, Separation of Compute and Storage in BigQuery, BigQuery Under The Hood, An Inside Await at BigQuery whitepaper.
- Parallel database systems: the future of loftier performance database processing (DeWitt & Gray, 1992)
- Column Oriented Database Systems (Harizopoulos, Abadi and Boncz, 2009)
What's happening in the BI world?
Join 15k+ people to go insights from BI practitioners around the earth. In your inbox. Every week. Learn more
No spam, ever. We respect your e-mail privacy. Unsubscribe someday.
Source: https://www.holistics.io/blog/the-rise-and-fall-of-the-olap-cube/
{kind=link}
Postar um comentário for "what are the steps to produce an olap cube"